
Slides from my RStanARM tutorial
Back in September, I gave a tutorial on RStanARM to the Madison R user’s group. As I did for my magrittr tutorial, I broke the content down into slide decks. They were:
- How I got into Bayesian statistics
- Some intuition-building about Bayes theorem
- Tour of RStanARM
- Where to learn more about Bayesian statistics
The source code and supporting materials are on Github.
Observations (training data)
The intuition-building section was the most challenging and rewarding, because I had to brush up on Bayesian statistics well enough to informally, hand-wavily teach about it to a crowd of R users. Like, I have good sense of how to fit these models and interpret them in practice, but there’s a gulf between understanding something and teaching about it. It was a bit of trial by fire 🔥.
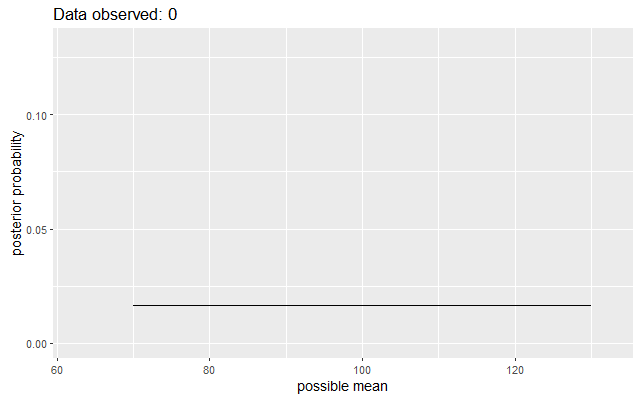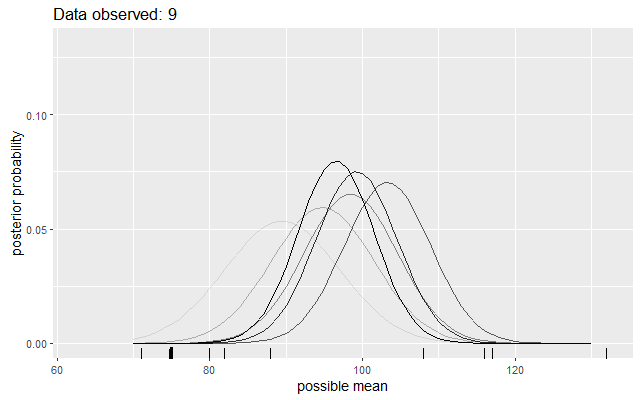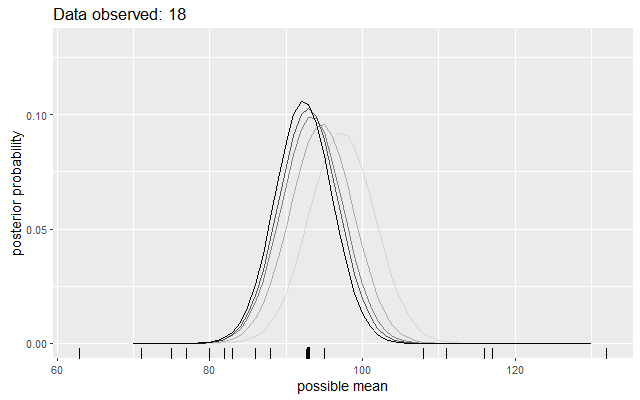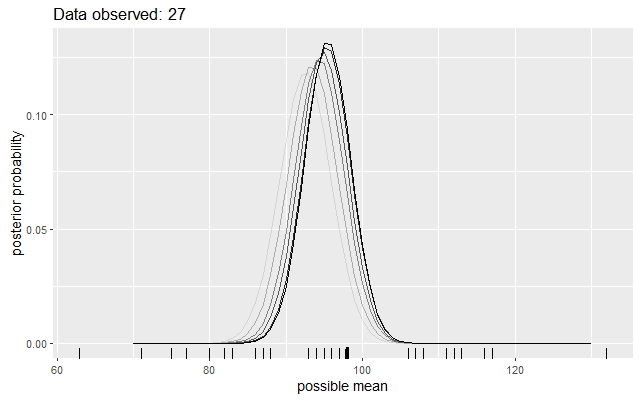
One thing I did was work through a toy Bayesian updating demo. What’s the mean of some IQ scores, assuming a standard deviation of 15 and a flat prior over a reasonable range values? Cue some plots of how the distribution of probabilities update as new data is observed.




See how the beliefs are updated? See how we retain uncertainty around that most likely value? And so on.
Naturally, I animated the thing—I’ll take any excuse to use gganimate.
{kind=link}
Someone asked a good question about what advantages these models have over classical ones. I find the models more intuitive1, because posterior probabilities are post-data probabilities. I also find them more flexible. For example, I can use a t-distribution for my error terms—thick tails! If I write the thing in Stan, I can incorporate measurement error into the model. If I put my head down and work really hard, I could even fit one of those gorgeous Gaussian process models. We can fit vanilla regression models or get really, really fancy, but it all kind of emerges nicely from the general framework of writing out priors and a likelihood definition.
Last knitted on 2022-05-27. Source code on GitHub.2
-
But I was taught the classical models first… I sometimes think that these models are only more intuitive because this is my second bite at the apple. This learning came more easily because the first time I learned regression, I was a total novice and had to learn everything. I had learn to about t-test, reductions in variance, collinearity, and what interactions do. Here, I can build off of that prior learning. Maybe if I learn everything again—as what? everything as a neural network?—it will be even more intuitive. ↩
-
.session_info #> ─ Session info ─────────────────────────────────────────────────────────────── #> setting value #> version R version 4.2.0 (2022-04-22 ucrt) #> os Windows 10 x64 (build 22000) #> system x86_64, mingw32 #> ui RTerm #> language (EN) #> collate English_United States.utf8 #> ctype English_United States.utf8 #> tz America/Chicago #> date 2022-05-27 #> pandoc NA #> #> ─ Packages ─────────────────────────────────────────────────────────────────── #> package * version date (UTC) lib source #> assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.2.0) #> cli 3.3.0 2022-04-25 [1] CRAN (R 4.2.0) #> crayon 1.5.1 2022-03-26 [1] CRAN (R 4.2.0) #> emo 0.0.0.9000 2022-05-25 [1] Github (hadley/emo@3f03b11) #> evaluate 0.15 2022-02-18 [1] CRAN (R 4.2.0) #> generics 0.1.2 2022-01-31 [1] CRAN (R 4.2.0) #> git2r 0.30.1 2022-03-16 [1] CRAN (R 4.2.0) #> glue 1.6.2 2022-02-24 [1] CRAN (R 4.2.0) #> here 1.0.1 2020-12-13 [1] CRAN (R 4.2.0) #> highr 0.9 2021-04-16 [1] CRAN (R 4.2.0) #> knitr * 1.39 2022-04-26 [1] CRAN (R 4.2.0) #> lubridate 1.8.0 2021-10-07 [1] CRAN (R 4.2.0) #> magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.2.0) #> purrr 0.3.4 2020-04-17 [1] CRAN (R 4.2.0) #> ragg 1.2.2 2022-02-21 [1] CRAN (R 4.2.0) #> rlang 1.0.2 2022-03-04 [1] CRAN (R 4.2.0) #> rprojroot 2.0.3 2022-04-02 [1] CRAN (R 4.2.0) #> rstudioapi 0.13 2020-11-12 [1] CRAN (R 4.2.0) #> sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.2.0) #> stringi 1.7.6 2021-11-29 [1] CRAN (R 4.2.0) #> stringr 1.4.0 2019-02-10 [1] CRAN (R 4.2.0) #> systemfonts 1.0.4 2022-02-11 [1] CRAN (R 4.2.0) #> textshaping 0.3.6 2021-10-13 [1] CRAN (R 4.2.0) #> xfun 0.31 2022-05-10 [1] CRAN (R 4.2.0) #> #> [1] C:/Users/Tristan/AppData/Local/R/win-library/4.2 #> [2] C:/Program Files/R/R-4.2.0/library #> #> ──────────────────────────────────────────────────────────────────────────────
Leave a comment